В предыдущей статье: https://blog.yakunin.dev/fluent-bit-docker-install/ мы рассматривали установку и настройку Fluent Bit. Как его установить, настроить парсинг логов, куда их передавать и как работать. В этой статье опишем его связь с Elasticsearch и Kibana для визуализации логов. Так как в прошлой статье мы запускали стек в Docker, продолжим эту славную традицию. И так, добавляем в docker-compose.yml загрузку и настройку Elasticsearch:
version: '2.8'
services:
fluent-bit:
image: fluent/fluent-bit
container_name: fluent-bit
volumes:
- ./conf:/fluent-bit/etc
- /var/log:/var/log
networks:
- elastic
elasticsearch:
image: elasticsearch:8.2.0
container_name: elasticsearch
ports:
- "9200:9200"
environment:
- network.host=0.0.0.0
- node.name=es01
- cluster.name=es-docker-cluster
- bootstrap.memory_lock=false
- cluster.initial_master_nodes=es01
- xpack.security.enabled=false
- xpack.ml.enabled=false
- xpack.graph.enabled=false
- xpack.watcher.enabled=false
- "ES_JAVA_OPTS=-Xms1G -Xmx1G"
networks:
- elastic
networks:
elastic:
driver: bridgeПеред запуском в файл /etc/sysctl.conf необходимо добавить запись vm.max_map_count=262144 и применить sysctl -p, в противном случае Elasticsearch может поругаться на нехватку этого значения. В любом случае, отладка это важный шаг, по этому после запуска не лишним будет сделать docker logs elasticsearch. И так после добавления, запускаем наш контейнер.
# docker compose up --detach
[+] Running 3/3
⠿ Network efk3_elastic Created 0.1s
⠿ Container fluent-bit Started 0.8s
⠿ Container elasticsearch Started 0.9s
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f26dfa996400 elasticsearch:8.2.0 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 9300/tcp elasticsearch
44a38c3cc7bd fluent/fluent-bit "/fluent-bit/bin/flu…" About a minute ago Up About a minute 2020/tcp fluent-bitОтлично, теперь мы можем проверить работу Elasticsearch:
# curl -X GET 'localhost:9200/'
{
"name" : "es01",
"cluster_name" : "es-docker-cluster",
"cluster_uuid" : "VMDH-5q2TSuLy7OXjz6T6A",
"version" : {
"number" : "8.2.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "b174af62e8dd9f4ac4d25875e9381ffe2b9282c5",
"build_date" : "2022-04-20T10:35:10.180408517Z",
"build_snapshot" : false,
"lucene_version" : "9.1.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}Хорошо, база у нас готова, можно проверить есть ли у нас индексы:
# curl -X GET 'localhost:9200/_cat/indices?v'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.sizeПока их нет, что логично, ведь мы не добавляли ни одной записи в наш лог. Добавим запись и проверим. Напомню, из конфигурационного файла fluent-bit.conf наш лог лежит по пути /var/log/fluet-bit.log Добавляем запись и проверяем:
# echo "Name: Yakunin V. Vasily Age: 42 City: Volgograd IP: 10.10.10.10" >> /var/log/fluent-bit.log
# curl -X GET 'localhost:9200/_cat/indices?v'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open fluent-bit LRAWZ3QGQpWTNycHTFrHqg 1 1 1 0 5.8kb 5.8kb
Отлично, индекс был создан и туда добавлена запись. Статус yellow говорит нам о том, что у нас только один экземпляр Elasricsearch что недопустимо в продуктовой среде, но для наших нужд, нам не нужен кластер. Достаточно одного экземпляра. Но, если почитать документацию на сайте elasticsearch то там описан именно кластер: https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html Хорошо, мы можем продолжать и проверим что хранит наш индекс:
# curl -X GET 'http://localhost:9200/fluent-bit/_search?pretty=true&q=*:*'
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "fluent-bit",
"_id" : "F6sC8IABqUkfy1FNbix4",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2022-05-23T08:22:12.277Z",
"name" : "Yakunin V. Vasily ",
"age" : 42,
"city" : "Volgograd",
"ip" : "10.10.10.10"
}
}
]
}
}Как видно наша запись успешно добавилась в базу и теперь проиндексирована, можно переходить к визуализации данных и добавлении в стек Kibana. Для этого редактируем наш docker-compose.yml:
version: '2.8'
services:
fluent-bit:
image: fluent/fluent-bit
container_name: fluent-bit
volumes:
- ./conf:/fluent-bit/etc
- /var/log:/var/log
networks:
- elastic
elasticsearch:
image: elasticsearch:8.2.0
container_name: elasticsearch
ports:
- "9200:9200"
environment:
- network.host=0.0.0.0
- node.name=es01
- cluster.name=es-docker-cluster
- bootstrap.memory_lock=false
- cluster.initial_master_nodes=es01
- xpack.security.enabled=false
- xpack.ml.enabled=false
- xpack.graph.enabled=false
- xpack.watcher.enabled=false
- "ES_JAVA_OPTS=-Xms1G -Xmx1G"
networks:
- elastic
kibana:
image: kibana:8.2.0
container_name: kibana
links:
- "elasticsearch"
ports:
- 5601:5601
environment:
ELASTICSEARCH_URL: http://elasticsearch:9200
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
networks:
- elastic
networks:
elastic:
driver: bridgeУдалим и создадим заново наш стек, данные при этом буду удалены, если мы хотим хранить данные после пересоздания контейнеров, нам необходимо пользоваться параметром volumes и передавать в него место хранения информации. Но в учебных целях мы не будем этого делать. Просто пересоздадим стек:
# docker compose down
[+] Running 3/3
⠿ Container fluent-bit Removed 2.4s
⠿ Container elasticsearch Removed 2.7s
⠿ Network efk3_elastic Removed 0.1s
# docker compose up --detach
[+] Running 4/4
⠿ Network efk3_elastic Created 0.1s
⠿ Container elasticsearch Started 1.0s
⠿ Container fluent-bit Started 1.0s
⠿ Container kibana Started 1.6sТеперь мы снова должны добавить запись в базу, а луче мы добавим их несколько, что бы было более наглядно.
# echo "Name: Yakunin V. Vasily Age: 42 City: Volgograd IP: 10.10.10.10" >> /var/log/fluent-bit.log
# echo "Name: Petrov P. Petr Age: 31 City: Moscow IP: 10.10.10.11" >> /var/log/fluent-bit.log
# echo "Name: Sidorov S. Sidor Age: 37 City: Minsk IP: 10.20.10.6" >> /var/log/fluent-bit.log
# curl -X GET 'http://localhost:9200/fluent-bit/_search?pretty=true&q=*:*'
{
"took" : 856,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "fluent-bit",
"_id" : "J1gP8IABSYRy5Al4lY6d",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2022-05-23T08:36:33.766Z",
"name" : "Yakunin V. Vasily ",
"age" : 42,
"city" : "Volgograd",
"ip" : "10.10.10.10"
}
},
{
"_index" : "fluent-bit",
"_id" : "KFgP8IABSYRy5Al4-o6s",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2022-05-23T08:36:59.833Z",
"name" : "Petrov P. Petr ",
"age" : 31,
"city" : "Moscow",
"ip" : "10.10.10.11"
}
},
{
"_index" : "fluent-bit",
"_id" : "KVgQ8IABSYRy5Al4d46r",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2022-05-23T08:37:32.237Z",
"name" : "Sidorov S. Sidor ",
"age" : 37,
"city" : "Minsk",
"ip" : "10.20.10.6"
}
}
]
}
}Данные в базе настало время визуализации. Заходим на http://localhost:5601/ и в левой панели переходим в самый низ, до опции Management.
Переходим в Stack Management и далее находим в меню DataView, кликаем на него что бы создать наш DataView.

В поле имя, необходимо ввести имя индекса, который создался автоматически, в данном случае это fluent-bit, звездочка означает маску захватывающую все, по этому можно написать и так fluent*, мы захватим индекс. Далее сохраняем его.
Теперь на боковом меню, пункта Аналитики, мы можем нажать на подпункт Discover что бы проверить наши записи.
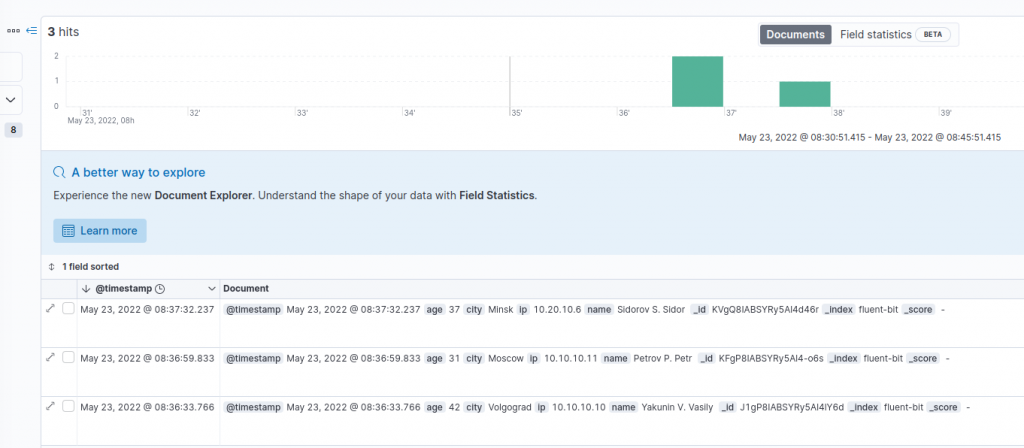
Я вижу все мои данные, теперь я могу создать для них дашборды настроить фильтры и т.д., об этом стоит написать отдельно. Но теперь вы можете видеть свои данные и работать с ними. Под итогом, мы добавляли записи в наш лог файл вручную через echo, но программа будет записывать логи самостоятельно и каждая новая строка попадающая в файл, будет обработана, распарсена, отдана в базу Elasticsearch и далее обработана уже Kibana. Так же стоит отметить что Grafana прекрасно работает с Elasticsearch и все данные можно визуализировать в ней. Об этом тоже стоит написать отдельно. Надеюсь эта статья немного помогла понять как все это работает.
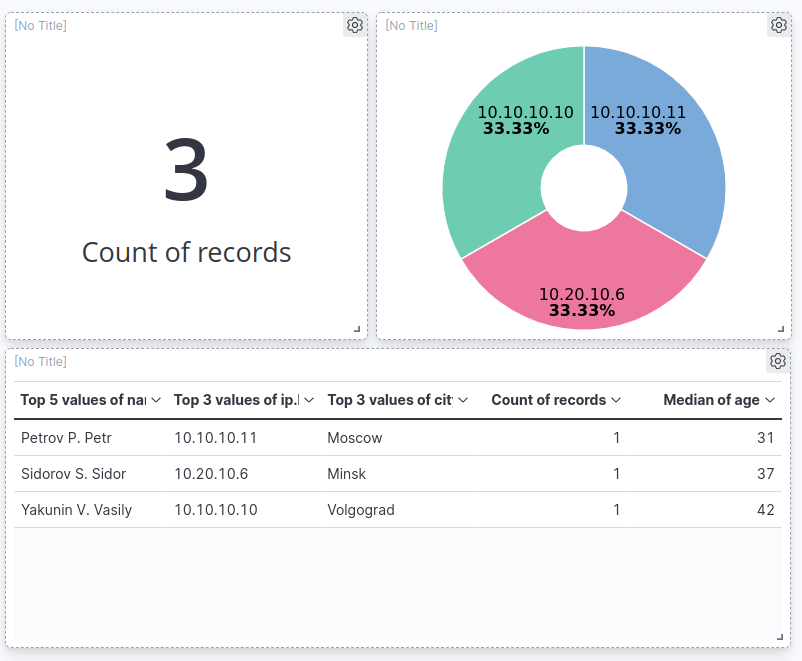
Я быстро набросал вот такой дашборд, что бы визуально отразить данные которые мы внесли в базу.