Как показала практика тема эта для многих интересна. Что ж, пожалуй стоит написать об этом ещё немного. Сегодня на примере разберем стандартный syslog, напишем простой парсер на Python с выводом обработанного текста в JSON. И так, начнем.
Допустим что наш файл syslog содержит только следующие строки:
Nov 16 12:08:06 altera 50-motd-news[1193189]: footprint of MicroK8s to make it the smallest full K8s around.
Nov 16 12:08:06 altera 50-motd-news[1193189]: https://ubuntu.com/blog/microk8s-memory-optimisation
Nov 16 12:08:06 altera systemd[1]: motd-news.service: Succeeded.
Nov 16 12:15:01 altera CRON[1194579]: (root) CMD (command -v debian-sa1 > /dev/null && debian-sa1 1 1)
Nov 16 12:17:01 altera CRON[1194978]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Nov 16 13:17:49 altera dbus-daemon[851]: [system] Activating via systemd: service name='org.freedesktop.PackageKit' unit='packagekit.service' requested by ':1.78'
Nov 16 13:17:49 altera systemd[1]: Starting PackageKit Daemon...
Nov 16 13:17:49 altera PackageKit: daemon start
Nov 16 13:17:49 altera dbus-daemon[851]: [system] Successfully activated service 'org.freedesktop.PackageKit'
Nov 16 14:17:01 altera CRON[1219211]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
В данном случае строку будем разбирать на 5 блоков, например, строка: Nov 16 12:08:06 altera systemd[1]: motd-news.service: Succeeded., будет разбита на дату (date) Nov 16 12:08:06, хост: (host) altera, демон (daemon) systemd, идентификатор процесса (id) 1, сообщение от демона (message) motd-news.service: Succeeded. Таким образом у нас должна получится конструкция:
Nov 16 12:08:06 altera systemd[1]: motd-news.service: Succeeded.
date: Nov 16 12:08:06
host: altera
daemon: systemd
id: 1
message: motd-news.service: Succeeded.Сначала создадим регулярное выражение:
(?P<date>[a-zA-Z].+\d+.\d+\W+\d+\W+\d+)\s(?P<host>\w+).((?P<daemon1>.*)\[(?P<id>\d+)\]:|(?P<daemon2>.*):)\s+(?P<message>.*)Теперь разберем весь этот набор символов. Оговорюсь сразу, данное регулярное выражение адаптировано под Python. Для других языков синтаксис создания групп будет немного отличаться, но сами выражения будут идентичными. И так. Первая группа date. Исходная строка: Nov 16 12:08:06 выражение для неё — (?P<date>[a-zA-Z].+\d+.\d+\W+\d+\W+\d+), разберем само выражение. ?P<date> создает группу которая получит значение выражения. Само выражение: [a-zA-Z].+\d+.\d+\W+\d+\W+\d+ рассмотрим его более подробно:
Nov 16 12:08:06 [a-zA-Z].+\d+.\d+\W+\d+\W+\d+ Сначала выбираем месяц он состоит из букв, заглавных и прописных, по этому к нему будет применено выражение [a-zA-Z] имея такое выражение будет захвачено Nov, далее идет точка, она захватывает любой символ, в том числе и пробел, далее идет знак плюса, который означает что нужно захватывать все что идет после точки, то есть сначала месяц, потом проблем (точка) и далее любые символы. После этого у нас следует \d+ что захватит число 16, так как \d — это любое число, знак + полностью захватит 16., после снова идет точка, любой символ, далее снова число, \d+ что захватит 12, далее у нас идет символ двоеточия, для него мы будем использовать \W+ то есть любой символ который будет не числом и не буквой, но не пробел. Далее конструкция повторяется для каждого последующего блока 80, :, 06. Таким образом выражение [a-zA-Z].+\d+.\d+\W+\d+\W+\d+ захватит Nov 16 12:08:06. Что бы объединить результат в группу нужно заключить выражение в скобки и дать название группы: (?P<date>). Таким образом все выражение с группой которое захватит только дату будет следующим: (?P[a-zA-Z].+\d+.\d+\W+\d+\W+\d+)
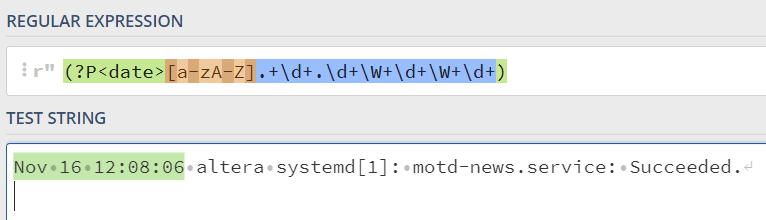
Далее нам необходимо захватить хост и создать для него группу. Так как между группой даты и группой хост есть пробел, мы будем использовать \s, что означает любой пробельный символ. Хорошо выражение для определения хоста: (?P\w+), рассмотрим, с названием групп и так уже понятно остается только \w+, что означает любые печатные символы, то есть буквы, вне зависимости от регистра. Можно было бы заменить \w+ на [a-zA-Z], но это слишком громоздко. Впрочем это можно применить и к дате, попробуйте. Значит, теперь наше выражение будет выглядеть так: (?P[a-zA-Z].+\d+.\d+\W+\d+\W+\d+)\s(?P\w+) что захватит дату и хост.
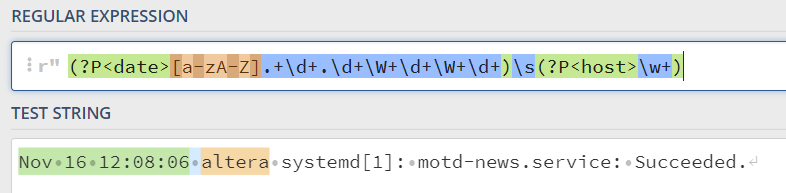
Теперь необходимо захватить демона, при этом нужно понимать, что демон может не иметь идентификатора, то есть какая-то операция которая попала в syslog, например: Nov 16 13:17:49 altera PackageKit: daemon start. Как же быть в этом случае? В этом случае мы создадим условие для выбора, если демон будет иметь идентификатор, то мы захватим как демон так и идентификатор, а если это только демон, то только демон. Пример посложнее чем предыдущие:
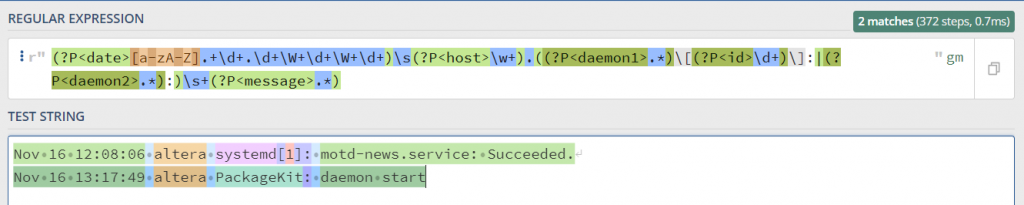
((?P<daemon1>.*)\[(?P<id>\d+)\]:|(?P<daemon2>.*):)Рассмотрим, первая группа захватывает любые символы до того пока не встретит символ [, то есть для systemd[1] это будет systemd, после чего мы создаем группу идентификатора и захватываем все цифры \d+ пока не встретим символ ], и вот тут наступает второе условие которое описано символом |, то есть выражение a | b, будет отдавать либо а, либо б. Но группа не может иметь одно и тоже название, по этому мы назвали её daemon2 и захватываем все символы пока не встретим двоеточие.

Как видите на примере сработало условие, в первой строке демон имеет идентификатор, во второй его нет, в первой мы захватили идентификатор, во второй ничего не делали так его нет. И все что нам остается захватить последнюю группу message.
(?P<message>.*)Она захватит все что идет после двоеточия в логах. Таким образом мы покрыли все строчки в логе.
А теперь напишем Python скрипт для парсинга лога и приведение его значений в json, это полезно если например данные надо передать в Elasticsearch или другую базу/обработчик. Таким образом вы можете писать свои выражение для filebat например, и парсить любые логи, любые строки получая только то, что вам нужно. И так:
!/usr/bin/python3.8
import re
import json
regex = r"(?P<date>[a-zA-Z].+\d+.\d+\W+\d+\W+\d+)\s(?P<host>\w+).((?P<daemon1>.*)\[(?P<id>\d+)\]:|(?P<daemon2>.*):)\s+(?P<message>.*)"
with open("/var/log/syslog", "r") as file:
for line in file:
r = re.search(regex, line)
if r:
if r.group('daemon1'):
print (json.dumps({ 'date':r.group('date'),
'host':r.group('host'),
'daemon':r.group('daemon1'),
'id':int(r.group('id')),
'message':r.group('message')
}, sort_keys=True, indent=5))
if r.group('daemon2'):
print (json.dumps({ 'date':r.group('date'),
'host':r.group('host'),
'daemon':r.group('daemon2'),
'message':r.group('message')
}, sort_keys=True, indent=4))
file.close()Краткое описание работы скрипта, мы загружаем 2 библиотеки, собственно обработчик регулярных выражений и обработчик json. это делается во 2-й и 3-й строке кода. Далее мы присваиваем переменной regex наше выражение которое мы собрали ранее. После чего открываем файл по пути /var/log/syslog, читаем его построчно и применяем выражение к каждой строке. Полученные группы мы помещаем в массив json, после чего закрываем файл. Вывод будет следующим: ( я взял свежий вывод напрямую из файла)
{
"daemon": "dbus-daemon",
"date": "Nov 17 12:39:22",
"host": "altera",
"id": 851,
"message": "[system] Successfully activated service 'org.freedesktop.fwupd'"
}
{
"daemon": "systemd",
"date": "Nov 17 12:39:22",
"host": "altera",
"id": 1,
"message": "Started Firmware update daemon."
}
You could certainly see your skills within the article you write.
The world hopes for more passionate writers such as you who aren’t afraid to mention how they believe.
Always go after your heart.
Aw, this was an incredibly nice post. Spending some time and actual effort to generate a top notch article… but what can I say… I put things off
a lot and don’t seem to get anything done.